从0到1使用 Kubernetes 系列(七):网络
本文是从 0 到 1 使用 Kubernetes 系列第七篇,上一篇《从 0 到 1 使用 Kubernetes 系列(六):数据持久化实战》 介绍了 Kubernetes 中的几种常用储存类型,本文将介绍 K8S 网络相关的内容。
不同宿主机上运行的容器并不能通过 IP 相互访问,那么 Kubernetes 是如何实现不同节点上 Pod 的互通?Pod 有生命周期,它的 IP 会随着动态的创建和销毁而动态变化,Kubernetes 又是怎样对外提供稳定的服务?今天就为大家一一解答这些疑问。
Docker 网络
先来看一下 Docker 中的网络。在启动 Docker 服务后,默认会创建一个 docker0 网桥(其上有一个 docker0 内部接口),它在内核层连通了其他的物理或虚拟网卡,这就将所有容器和本地主机都放到同一个物理网络。
Docker 默认指定了 docker0 接口 的 IP 地址和子网掩码,让主机和容器之间可以通过网桥相互通信,它还给出了 MTU(接口允许接收的最大传输单元),通常是 1500 Bytes,或宿主主机网络路由上支持的默认值,这些值都可以在服务启动的时候进行配置。
root@ubuntu:/root# ifconfig
...
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 0.0.0.0
ether 02:42:d2:00:10:6c txqueuelen 0 (Ethernet)
...
root@ubuntu:/root# docker inspect busybox
···
"IPAddress": "172.17.0.2",
···
为了实现上述功能,Docker 主要用到了 linux 的 Bridge 、Network Namespace 、VETH。
- Bridge 相当于是一个虚拟网桥,工作在第二层网络。也可以为它配置 IP,工作在三层网络。docker0 网关就是通过 Bridge 实现的。
- Network Namespace 是网络命名空间,通过 Network Namespace 可以建立一些完全隔离的网络栈。比如通过 docker network create xxx 就是在建立一个 Network Namespace
- VETH 是虚拟网卡的接口对,可以把两端分别接在两个不同的 Network Namespace 中,实现两个原本隔离的 Network Namespace 的通信。
所以总结起来就是:Network Namespace 做了容器和宿主机的网络隔离,Bridge 分别在容器和宿主机建立一个网关,然后再用 VETH 将容器和宿主机两个网络空间连接起来。但这都是在同一个主机上的网络实现,如果想要在多台主机上进行网络就得看看下面介绍的 Kubernetes 网络。
Kubernetes 网络
Kubernetes 为了解决容器的“跨主通信”问题,提出了很多解决方案。常见思路有两种:
- 直接在宿主机上建立不同宿主机上子网的路由规则;
- 通过特殊的网络设备封装二层数据帧,根据目标 IP 地址匹配到对应的子网找到对应的宿主机 IP 地址,最后将转发 IP 包,目的宿主机上同样的特殊网络设备完成解封并根据本机路由表转发。
Flannel
大家所熟知的 Flannel 项目是 CoreOS 公司推出的容器网络解决方案。它本身只是一个框架,为开发者提供容器网络功能的是 Flannel 的后端实现。目前有如下三种具体实现:
- UDP
- VXLAN
- host-gw
下面的三层网络指的是七层网络模型中的底部的三层:网络层、数据链路层和物理层。
UDP 模式是最早支持,性能最差,但最容易理解和实现的容器跨主网络方案。Flannel UDP 模式提供的是一个三层的覆盖网络:首先对发出端的 IP 包进行 UDP 封装,然后在接受端进行解封拿到原始的 IP 包,进而把这个包转发给目标容器。它相当于在两个容器之间打通一条“隧道”,使得两个容器可以直接使用 IP 通信,而不关心容器和宿主机的分布情况。
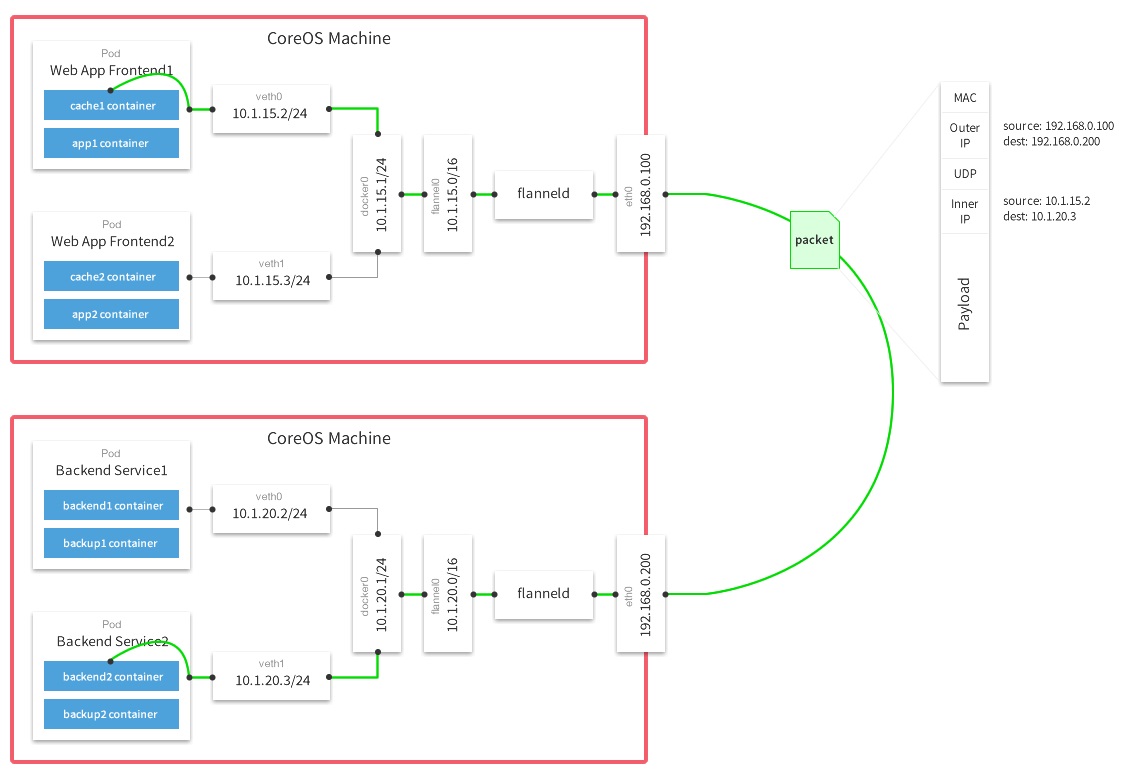
因为 Flannel 进行 UDP 封装和解封都是在用户态完成,而在 Linux 系统中上下文切换和用户态操作的代价非常大,这就是它性能不好的主要原因。
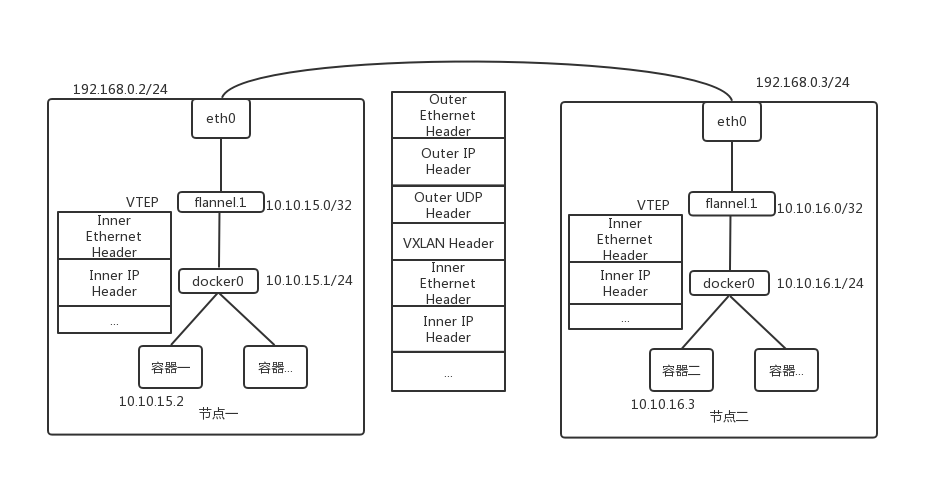
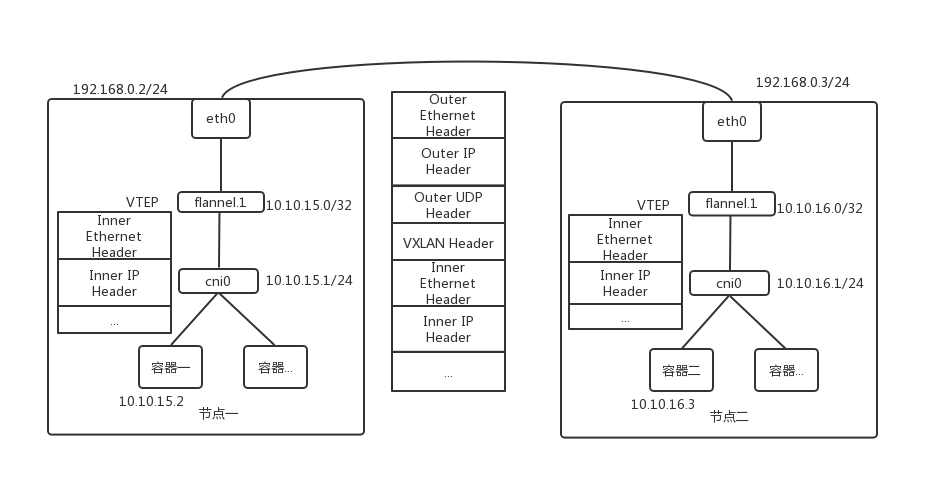
VXLAN 即 Virtual Extensible LAN(虚拟可扩展局域网),是 Linux 内核本身就支持的一种网络虚拟化技术。VXLAN 在内核态就完成了上面的封装和解封工作,通过与 UDP 模式类似的“隧道”机制,构建出覆盖网络(Overlay Network),使得连接在这个 VXLAN 二层网络的“主机”可以像在局域网自由通信。
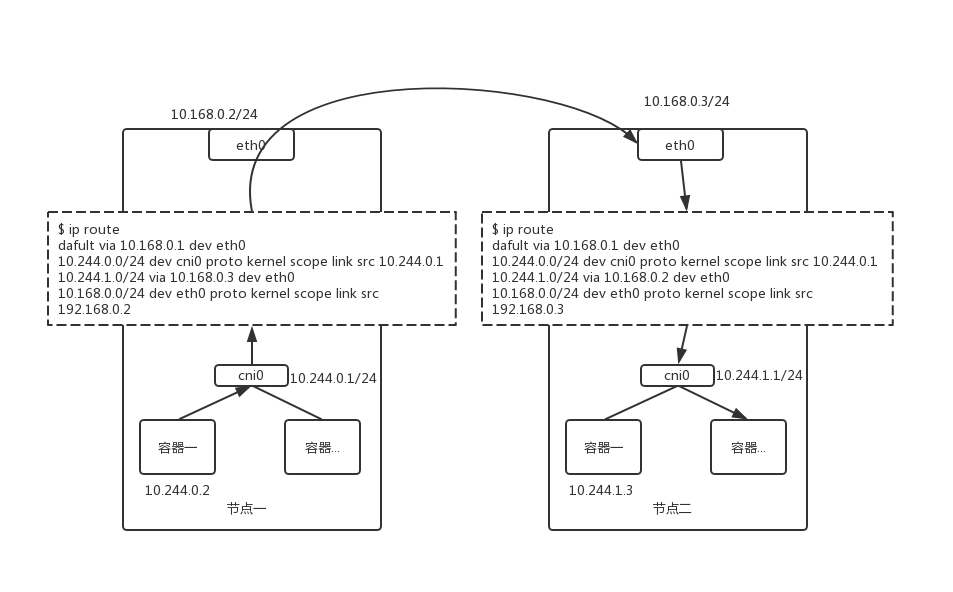
host-gw 模式的工作原理是将每一个 Flannel 子网的下一跳设置为该子网对应的宿主机 IP 地址。
也就是说,这台“主机”(host)会充当这条容器通信路径里的“网关”(Getway)。_Flannel host-gw 模式必须要求集群宿主机之间是二层连通的_。
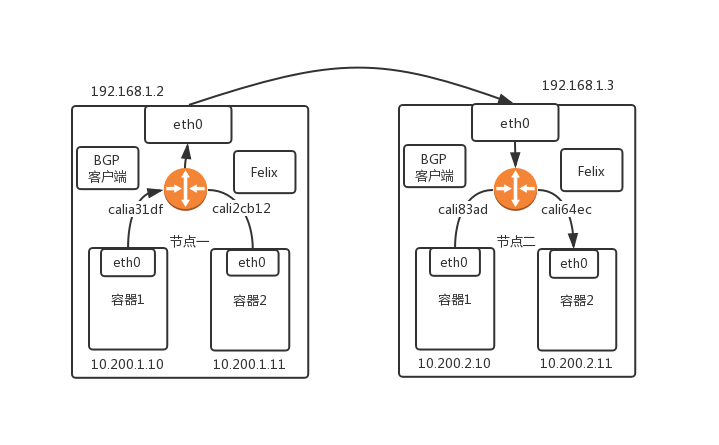
Calico
Calico 项目提供的网络解决方案与 Flannel Host-gw 模式同理。但是不同于 Flannel 通过 Etcd 和宿主机的 flanneld 来维护路由信息得做法,Calio 项目使用 BGP(边界网关协议) 来自动的在整个集群中分发路由消息。它由三部分组成:
Calico 的 CNI 插件:这是 Calico 与 Kubernetes 对接的部分。 Felix:它是一个 DaemonSet,负责在宿主机插入路由规则,以及维护 Calico 所需的网络设备等。 BIRD:它是 BGP 的客户端,负责在集群里分发路由规则信息。
除了对路由信息的维护方式之外,Calico 项目和 Flannel 的 host-gw 另一个不同是它不会在宿主机上创建任何网桥设备。
CNI(容器网络接口)
CNI)是 CNCF 旗下的一个项目,由一组用于配置 Linux 容器的网络接口的规范和库组成,同时还包含了一些插件。CNI 仅关心容器创建时的网络分配,和当容器被删除时释放网络资源。其基本思想为: Kubernetes 在启动 Infra 容器之后,就可以直接调用 CNI 网络插件,为这个 Infra 容器的 Network Namespace 配置符合预期的网络栈。
Kubernetes 使用 CNI 接口,维护一个单独的网桥来代替 docker0。这个网桥就叫做 CNI 网桥,它在宿主机上的默认名称是:cni0。以 Flannel 的 VXLAN 模式为例,在 Kubernetes 环境里,它的工作方式没有变化,只是 docker0 网桥替换成了 CNI 网桥。CNI 网桥只是接管所有 CNI 插件负责的,即 Kuberntes 创建的容器(Pod)。
Service
Kubernetes 中 Pod 有生命周期,它的 IP 会随着动态的创建和销毁而动态变化,不能稳定的提供服务。Kubernetes Service 定义这样一种抽象:一个 Pod 的逻辑分组,一种可以访问它们的策略。开发者可以通过一个 Service 的入口地址访问其背后的一组 Pod。一旦 Service 被创建,Kubernetes 就会自动为它分配一个可用的 Cluster IP,在 Service 的整个生命周期中它的 Cluster IP 都不会发生改变。这样就解决了分布式集群的服务发现。
一个典型的 Service 定义如下:
apiVersion: v1
kind: Service
metadata:
name: nginx
spec:
selector:
app: nginx
ports:
- nmae: dafault
protocol: TCP
port: 8000
targetPort: 80
在这个 Service 例子中,笔者使用 selector 字段声明这个 Service 只代理 app=nginx 标签的 pod。这个 Service 的 8000 端口代理 Pod 的 80 端口。
然后定义应用 Delpoyment 如下:
apiVersion: v1
kind: Delpoyment
metadata:
name: nginx
spec:
selector:
matchLabels:
app: nginx
replicas: 3
template:
meatdata:
lalels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containers: 80
protocol: TCP
被 selector 选中的 Pod,就被称为 Serivce 的 Endpoints,你可以使用 kubectl get ep 查看它们,如下所示:
$ kubectl get endpoints nginx
NAME ENDPOINTS AGE
nginx 172.20.1.16:80,172.20.2.22:80,172.20.2.23:80 1m
通过该 Service 的 VIP 10.68.57.93 地址,就可以访问到它所代理的 Pod:
$ kubectl get svc nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx ClusterIP 10.68.57.93 <none> 80/TCP 1m
$ curl 10.68.57.93
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
......
<h1>Welcome to nginx!</h1>
......
</html>
这个 VIP 地址是 Kubernetes 自动为 Service 分配的。访问 Service 的 VIP 地址和代理的 80 端口,它就为我们返回了默认的 nginx 页面,这种方式称为:Cluster IP 模式的 Service。
集群外访问 Service
Servcie 的访问信息在 kubernates 集群外无效,因为所谓的 Service 的访问接口,实际上是每台宿主机上由 kube-proxy 生成的 iptables 规则,以及 kube-dns 生成的 DNS 记录。
解决外部访问 Kubernetes 集群里创建的 servcie 有以下几种方法:
- NodePort
- LoadBalancer
NodePort 方法
下面是 NodePort 的例子:
apiVersion: v1
kind: Service
metadata:
name: my-nginx
labels:
run: my-nginx
spec:
type: NodePort
ports:
- name: http
nodePort: 30080
port: 8080
targetPort: 80
protocol: TCP
在这个 Service 定义中,声明它的类型为 type=NodePort。此时在 ports 字段中声明了 Service 的 8080 端口代理 Pod 的 80 端口。
如果你不显示声明 nodePort 字段,Kubernetes 会为你随机分配可用端口来设置代理,这个端口的范围默认为:30000-32767。这里设置为 30080。
这里就可以如此访问这个 service:
<任何一台宿主机 IP 地址>:30080
LoadBalancer
这种方法适用于公有云上的 Kubernetes 服务,通过指定一个 LoadBalancer 类型的 Service 实现。
apiVersion: v1
kind: Service
metadata:
name: example-service
spec:
ports:
- port: 8765
targetPort: 9379
selector:
app: example
type: LoadBalancer
创建 Service 时,你可以选择自动创建云网络负载均衡器。这提供了一个外部可访问的 IP 地址,只要您的群集在受支持的云环境中运行,就可以将流量发送到群集节点上的正确端口。
Ingress
为代理不同后端 Service 而设置的路由规则集合就是 Kubernetes 里的 Ingress。
举一个例子,这里有一个订阅系统,它的域名是:https://wwww.example.com 。其中 http://www.example.com/book 是订书系统,https://www.example.com/food 是订餐系统。这两个系统分别由 book 和 food 两个 Deployment 来提供服务。
apiVersion: v1
kind: Ingress
metadata:
name: example-ingress
spec:
tls:
- hosts:
- www.example.com
secretName: example-secret
rules:
- host: www.example.com
http:
paths:
- path: book
backend:
serviceName: book-svc
servicePort: 80
- path: /food
backend:
serviceName: food-svc
servicePort: 80
这个 yaml 文件值得关注的 rules 字段,它叫作:IngressRules。
IngressRule 的 Key 就是 host,它必须是一个标准域名格式的字符串,不能是 IP 地址。
host 字段定义的值就是 Ingress 的入口,也就是说当用户访问 www.example.com 的时候,实际上访问到的是这个 Ingress 对象。Kubernetes 就能根据 IngressRule 进行下一步转发,这里定义两个 path,它们分别对应 book 和 food 这个两个 Deployment 的 Service。
由此不难看出,Ingress 对象其实就是 Kubernetes 项目对“反向代理”的一种抽象。
总结
今天这篇文主要介绍了 Kubernetes 集群实现容器跨主机通信的几种方式的原理,并且介绍了如何使用 Service 对外界提供服务。
更多 Kubernetes 相关文章,点击蓝字可阅读:
- 从 0 到 1 使用 Kubernetes 系列——Kubernetes 入门
- 从 0 到 1 使用 Kubernetes 系列(二)——安装工具介绍
- 从 0 到 1 使用 Kubernetes 系列(三):使用 Ansible 安装 Kubernetes 集群
关于猪齿鱼
Choerodon 猪齿鱼是一个全场景效能平台,基于 Kubernetes 的容器编排和管理能力,整合 DevOps 工具链、微服务和移动应用框架,来帮助企业实现敏捷化的应用交付和自动化的运营管理的平台,同时提供 IoT、支付、数据、智能洞察、企业应用市场等业务组件,致力帮助企业聚焦于业务,加速数字化转型。
大家也可以通过以下社区途径了解猪齿鱼的最新动态、产品特性,以及参与社区贡献:
作者:易大强
出处:Choerodon
欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。